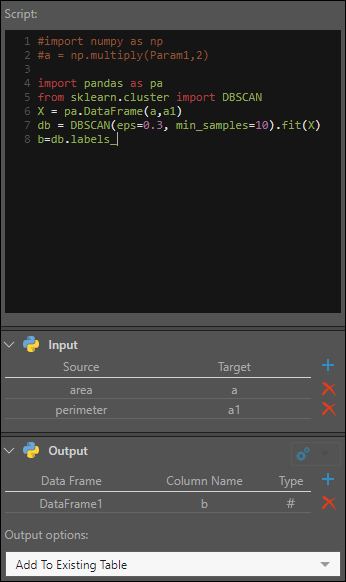
DBSCAN Clustering
In this example, an eye-ware company wants to use DBSCAN clustering to cluster distances of their customers to each other.
They want to group data points together based on two conditions: when their distance from the other data points in the cluster does not exceed 0.3km; and when there are at least 10 data points in the cluster.
import pandas as pa from sklearn.cluster import DBSCAN X = pa.DataFrame(a,a1) db = DBSCAN(eps=0.3, min_samples=10).fit(X) b=db.labels_
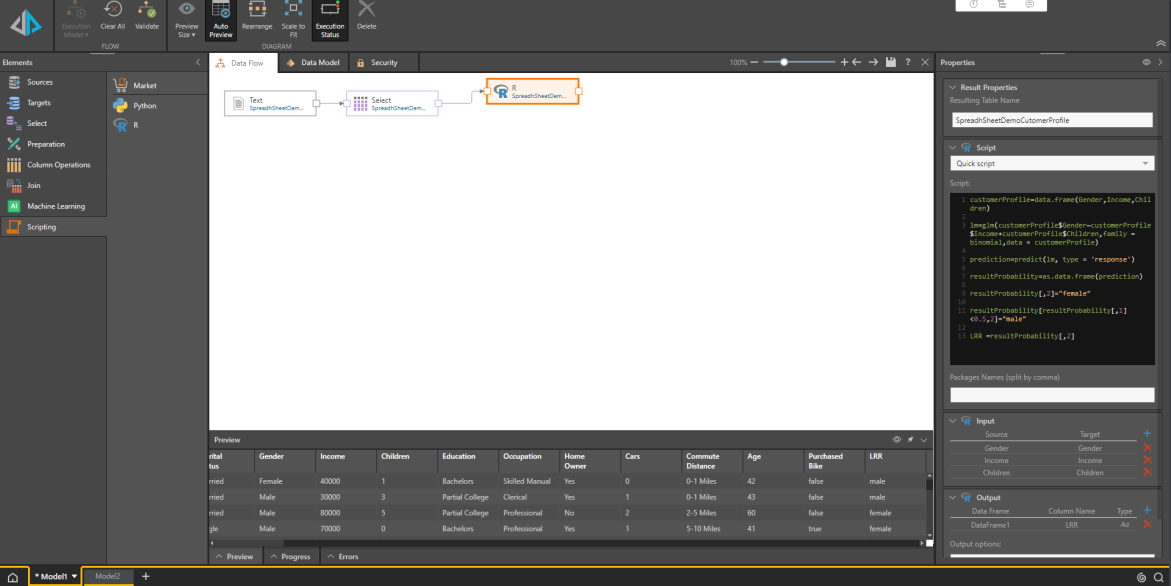
Get Logistic Regression
Say we're a retailer with an online store, and we want to predict the gender of visitors to our website based on some information that we collect about them. In this example, we'll use a logistical regression to make the prediction based on the visitor's income and number of children. The predictions will be added as a column to our table.
After adding the R node; under Input, click the plus sign and select From: Gender, and To: Gender. Note that here we are adding a Gender input, so that we can compare the results with the actual gender.
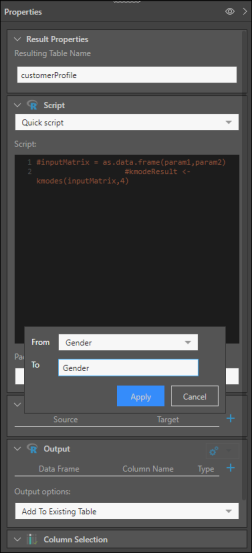
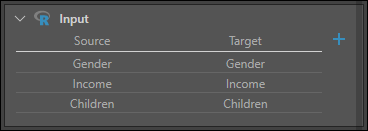
Click Apply, and add two more columns under Input: one for Income, and another for Children.
Add the following script in the script window:
customerProfile=data.frame(Gender,Income,Children)
lm=glm(customerProfile$Gender~customerProfile$Income+customerProfile$Children,family = binomial,data = customerProfile)
prediction=predict(lm, type = 'response')
resultProbability=as.data.frame(prediction)
resultProbability[,2]="female"
resultProbability[resultProbability[,1]<0.5,2]="male"
LRR =resultProbability[,2]
Click the plus sign under Output to add the output column:
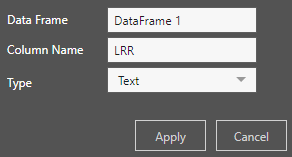
Preview the table to see the new column.